결측치
-데이터 수집과정에서 값이 기록되지 않은 것
-넘파이 배열에서는 결측치를 na.nan으로 표현
-판다스 데이터프레임에서는 결측치를 NaN으로 표현
1.결즉치 처리
pd.isna(df) #결즉치 위치 확인(isna(): 각 값의 결측 유무를 나타냄)pd.isna(df).sum() #열별 결측치 개수 확인
df_drop_nan = df.dropna() #행별로 모든 결측치 제거 ( dropna(): 결측치 제거)
df_drop_nan
df_0 = df['C'].fillna(0) # 숫자로 'C'열 결즉치를 0으로 대체 (fillna(): 숫자 결측치 대체)
print(df_0)
-------------------------------------------------------------------
df_missing = df['C'].fillna('missing') # 숫자로 'C'열 결즉치를 missing으로 대체 (fillna(): 문자열 결측치 대체)
df_missing
# mean()은 df각 열의 평균을 나타냄 # 평균으로 결즉치 대체
df_mean = df.fillna(df.mean())
print(df,'\n')
print(df_mean)
2.결측치 채우기

1. 평균 구하기
Ave=df.mean()이상치
-데이터셋에서 범위를 크게 벗어난 값
1. 이상치 제거
사분위수
- Q1 (제1사분위수): 데이터의 하위 25% 지점,
- Q2 (제2사분위수): 데이터의 중앙값, 즉 전체 데이터의 50%
- Q3 (제3사분위수): 전체 데이터의 75%
- Q3 (제4사분위수): 100%
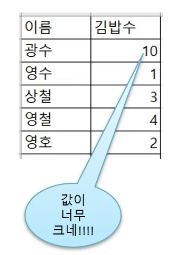
Q1 = df['김밥수'].quantile(0.25) #1사분위수(25%)-> 2
Q2 = df['김밥수'].quantile(0.5) #2사분위수(50%)-> 3
Q3 = df['김밥수'].quantile(0.75) #3사분위수(75%)-> 4
Q4 = df['김밥수'].quantile(1) #4사분위수(100%)-> 10
IQR(Interquartile Range) : 데이터의 분포에서 중심부의 폭을 측정 IQR = Q3-Q1
Q3-Q1 => 4-2=>2- 이상치 기준 설정: IQR을 기반으로 이상치의 경계를 설정합니다. 일반적으로는 IQR의 1.5배를 사용하여 이상치를 판단합니다. 이때의 기준은 다음과 같습니다:
-하한 경계: Q1−1.5×IQR
-상한 경계: Q3+1.5×IQR
Q1−1.5×IQR => 2-3=>-1 # -1보다 작은 값이 없음
Q3+1.5×IQR => 4+3=> 7 # 7보다 큰 값인 10이 이상치가 됨
<IQR 기법 적용한 이상치 제거 절차>
1.IQR 값 추출
import pandas as pd # pandas 라이브러리를 불러옵니다.
# 데이터 리스트를 정의합니다.
data = [0, 2, 4, 8, 10, 21]
# DataFrame을 생성하고 'Values'라는 열 이름을 지정합니다.
df = pd.DataFrame(data, columns=['Values'])
# Q1(제1사분위수, 25% 지점)을 계산합니다.
q1 = df['Values'].quantile(0.25)
# Q3(제3사분위수, 75% 지점)을 계산합니다. (변수 이름을 q3로 수정해야 합니다.)
q3 = df['Values'].quantile(0.75)
# Q1 값을 출력합니다.
print('Q1', q1)
# Q3 값을 출력합니다.
print('Q3', q3)
# IQR(사분위 범위)을 계산합니다: Q3 - Q1
iqr_Value = q3 - q1
# IQR 값을 출력합니다.
print('iqr', iqr_Value)
2. 최대값, 최소값 추출
upper_V = q3 + 1.5 * iqr_Value
Lower_V = q1 - 1.5 * iqr_Value
print(upper_V,'/', lower_V)
3.이상치 제거
df_iqr = df[(df['Values']<upper_V) &(df['Values'] > lower_V)]
df_iqr정규화
-값을 0부터 1까지의 값으로 전환
1. 순서대로 나열

=> 1, 2, 3, 4, 10
- 최대값: 10
- 최소값: 1

X’(1) = (1-1)/(10-1) //0
X’(2) = (2-1)/(10-1) //0.1
X’(3) = (3-1)/(10-1) //0.2
X’(4) = (4-1)/(10-1) //0.3
X’(10) = (10-1)/(10-1) //1
1.데이터 정규화
import pandas as pd
personA = [160, 180, 150,190]
df = pd.DataFrame(personA, columns=['키'])
df['정규화키'] = (df['키'] - df['키'].min( )) / (df['키'].max( ) - df['키'].min( ))
df
출처: 고수정 교수님 수업자료 참고
'데이터 분석' 카테고리의 다른 글
| 상관관계분석 (0) | 2024.11.30 |
|---|---|
| 웹 크롤링 기초 (0) | 2024.11.23 |
| 1. 데이터 분석 (0) | 2024.09.21 |
| python기초 정리 (0) | 2024.09.21 |