
데이터 베이스(Datavase)
: 다양한 데이터 저장 및 관리 방법 제공
1. 데이터와 정보
- 데이터: 문자, 숫자, 이미지, 영상 등 원시 자료
- 정보 (information): 데이터를 가공해서 의미와 가치를 부여한 것
2. 데이터 베이스
- 정의: 필요에 의해 데이터를 특정 공간에 지속적으로 모아놓은 것
- DBMS(Database Management System): 데이터베이스를 관리하는 시스템, Oracle, MySQL, Microsoft SQL Server, PostgreSQL, MongoDB, Redis, IBM DB2 등이 포함됨.
(1. Oracle: 기업용 데이터 베이스, 강력한 성능과 보안 기능 제공
2. MySQL: 오픈 관계형 데이터 베이스, 주로 웹 애플리케이션에 사용
3.Microsoft SQL Server: 마이크로소프트에서 개발한 관계형 데이터베이스
4. PostgreSQL: 오픈 소스 객체 관계형 데이터베이스
5. MongoDB: 오픈 소스 NoSQL데이터베이스, 문서 지향 데이터 모델 사용
6.Redis: 인메모리 데이터 구조 저장소, 주로 캐시나 세션 저장소로 사용
7. IBM DB2: IBM에서 개발한 관계형 데이터베이스)
3. SQL(Structured Query Language)
- 정의: 데이터베이스에서 데이터를 조작하는 데 사용하는 언어.
- 사용예: 데이터 검색, 삽입, 업데이트 및 삭제 작업에 사용됨.

4. 데이터베이스 모델 유형
- 계층형 데이터베이스: 1:N의 트리 구조로, 데이터 구조 변경에 유연함이 부족한 1970년대 시스템.
- 네트워크형 데이터베이스: 초기 데이터베이스 모델로, 복잡한 1:N, 1:1, N:N 구조를 가짐.
- 관계형 데이터베이스: 현재 가장 많이 사용되는 모델로, 데이터를 열과 행의 형태로 구성하며 논리적 관계를 활용. 예시로는 MySQL, PostgreSQL, Oracle 등이 있음.
- 객체지향형 데이터베이스: 객체 단위(데이터+메소드)로 구성되며, OOP(Object-Oriented Programming, 객체 지향 프로그래밍)와 함께 발전한 모델.
- NoSQL 데이터베이스: 비관계형 데이터베이스로, 구조가 정해져 있지 않아 유연성 및 확장성이 뛰어남. 온라인 게임이나 전자상거래 앱 등에 주로 사용.
5. 관계형 vs 비관계형 데이터베이스
- 관계형 데이터베이스:
-데이터는 행과 열로 구성된 테이블에 저장됨.
-규칙에 따라 데이터를 입력하고 SQL을 통해 조작.
-트랜잭션 관리를 위해 ACID(원자성, 일관성, 격리성, 내구성) 속성을 따름. - 비관계형 데이터베이스 (NoSQL):
-데이터는 컬렉션 또는 문서의 형식으로 저장됨.
-정해진 형식이 없고 유연성을 제공, JOIN 및 복잡한 쿼리 지원 불가.
-대량 데이터 처리에 수평적 확장 가능.
6. SQL과 NoSQL의 비교
7. 정형, 비정형, 반정형 데이터
- 정형 데이터: 미리 정해진 형식과 구조를 가진 데이터 (ex: RDBMS)
- 비정형 데이터: 구조 없이 저장된 동영상, 이미지 등 (ex: NoSQL)
- 반정형 데이터: 데이터 구조 정보가 데이터와 함께 제공되는 형태 (ex: XML, JSON)
NoSQL 데이터베이스 유형
1. Key-Value 데이터베이스
- 특징:
간단한 구조로, 데이터는 키와 값 쌍으로 저장됨
높은 확장성과 성능을 제공
대량의 데이터와 높은 트래픽을 처리하는 데 적합 - 예시 서비스:
-AWS DynamoDB: 완전 관리형 Key-Value 데이터베이스 서비스로, 자동으로 데이터의 분산과 복제를 관리
-Redis: 인메모리 데이터 구조 저장소로, 키-값 쌍을 빠르게 저장하고 검색할 수 있음
2. Graph 데이터베이스
- 특징:
데이터 간의 복잡한 관계를 관리하기 위해 설계됨
노드와 엣지의 형태로 데이터가 저장되어 개체 간의 관계를 표현
소셜 네트워크 및 추천 시스템과 같은 복잡한 데이터 관계 분석에 유용 - 예시 서비스:
Amazon Neptune: 관계형 데이터를 그래프로 저장하여 빠른 쿼리 성능을 제공
3. Document 데이터베이스
- 특징:
JSON과 유사한 형식으로 비정형 또는 반정형 데이터를 저장
사전 정의된 스키마가 없어 유연하게 데이터 모델링 가능 - 예시 서비스:
MongoDB: 데이터가 JSON과 유사한 문서 형태로 저장되어 유연한 데이터 구조 제공
Amazon DocumentDB: MongoDB와 호환되는 완전 관리형 문서 데이터베이스
4. Column 데이터베이스
- 특징:
고정된 스키마가 없는 컬럼 중심의 데이터 저장 방식
대량의 데이터를 효과적으로 관리 - 예시 서비스:
Apache Cassandra: 고성능 및 확장성을 제공하는 분산형 Column 스토리지 시스템
- 관계형 데이터베이스: Amazon RDS, Amazon Aurora
- 비관계형 데이터베이스: Amazon DynamoDB
- 인메모리 데이터베이스: Amazon ElastiCache
- 데이터 웨어하우스: Amazon Redshift
Amazon RDS (Relational Database Service)
- 개요: AWS에서 관계형 데이터베이스를 쉽게 설정하고 운영할 수 있는 서비스, 다양한 데이터베이스 엔진을 지원하며, 필요한 리소스에 따라 확장이 가능
- 특징
-선택 가능한 데이터베이스 엔진: Aurora, PostgreSQL, MySQL, MariaDB, Microsoft SQL Server, Oracle, IBM Db2
-자동화된 백업 및 소프트웨어 관리
-장애 감지 및 복구 기능 제공
-사용자가 직접 데이터베이스를 제어할 수는 없지만, 백업 스냅샷 생성 및 복원 가능
-읽기 전용 복제본(Read Replica) 기능으로 읽기 확장 가능
-AWS IAM을 통한 접근 제어
-가상 사설 클라우드(VPC)에서 데이터베이스 배치 가능
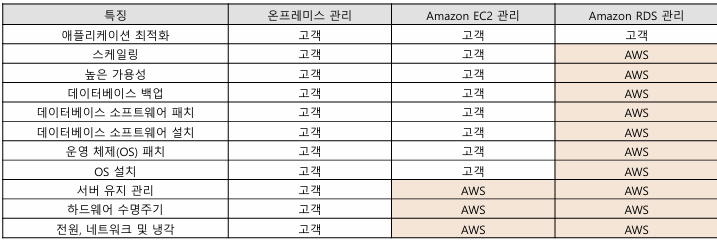
Amazon RDS 관련관리모델
- 온프레미스배포
•사용자가직접관리
•장비운영, OS 설치및운영, 데이터베이스솔루션설치및운영까지모두담당
- AmazonEC2배포
• AWS EC2 서버에 데이터베이스 솔루션을 설치하고 운영
•장비운영, OS 설치및운영은AWS가담당하고, 데이터베이스솔루션의설치및운영은사용자담당
인스턴스 클래스
- 인스턴스 유형:
-EC2와 유사하게 다양한 크기 제공: micro, small, medium, large, xlarge, 2xlarge, 4xlarge, 8xlarge, 16xlarge. - 범용(General Purpose) 인스턴스:
-시리즈: db.t4g, db.t3, db.m6g, db.m5.
-균형 잡힌 컴퓨팅, 메모리, 네트워크 리소스 제공.
-일반적인 데이터베이스 워크로드에 적합. - 메모리 최적화(Memory Optimized) 인스턴스:
-시리즈: db.r6g, db.r5.
-메모리 집약적 워크로드에 고성능 제공.
-대규모 인메모리 처리 애플리케이션에 적합. - 성능 최적화(Performance Optimized) 인스턴스:
-시리즈: db.x2g, db.z1d.
-고성능 데이터베이스 워크로드에 최적화.
-높은 처리량이 요구되는 엔터프라이즈 애플리케이션에 적합.
RDS 배포
- Read Replica (읽기 전용 복제본)
-목적: 읽기 작업을 더 많이 처리하기 위해 사용.
-특징:
-최대 5개의 Read Replica 생성 가능.
-쓰기는 메인 데이터베이스에서만 가능.
-비동기 복제로 인해 정합성 문제 발생 가능.
-부하 분산 및 데이터 백업 기능 제공. - Multi-AZ (다중 가용 영역)
-목적: 고가용성을 위한 장애 복구.
-특징:
-여러 가용 영역에 복제본을 구성하여 동기식 복제를 수행.
-메인 데이터베이스에 장애가 발생하면 복제본 데이터베이스로 자동 복구 (Failover).
-복제본 데이터베이스는 장애 발생 전까지는 액세스할 수 없음. - Multi-Region (다중 지역)
-목적: 전 세계 여러 지역에 DB 인스턴스를 생성하여 지연 시간 축소 및 재해 복구(DR) 지원.
-특징: 각 리전에 배포된 데이터베이스를 활용하여 애플리케이션 성능 향상.
Amazon Aurora
- AWS 관계형 데이터베이스: AWS에 최적화된 관계형 데이터베이스.
- 엔진 선택: MySQL 또는 PostgreSQL 중 선택 가능.
- 자동 용량 확장: 스토리지가 10GB 단위로 자동 확장되며, 최대 128TB까지 지원.
- 읽기 전용 복제본: 최대 15개의 읽기 전용 복제본 제공 (RDS는 최대 5개).
- 성능:
RDS MySQL에 비해 최대 5배 성능 향상.
RDS PostgreSQL에 비해 최대 3배 성능 향상. - 비용: RDS보다 약 20% 비쌈 (프리티어 없음).
- 효율성: 성능과 효율성 측면에서 RDS보다 Aurora 선택 가능.
- 호환성: MySQL 및 PostgreSQL로 쉽게 이전 가능하며, 기존 SQL 문 사용 가능.
DynamoDB
- 비관계형 데이터베이스: 키-값 데이터베이스 (NoSQL).
- 데이터 저장 방식: 서로 연결되지 않는 개별 형태로 저장, 복잡하고 비구조화된 데이터에 적합.
- 고가용성: 완전 관리형 데이터베이스로, 3개의 가용 영역(AZ)에 복제본 운영.
- 빠른 처리 성능: 구조가 단순하여 대규모 환경에서도 일관되게 10ms 미만의 낮은 지연 시간(low latency) 제공.
- 서버리스: 별도의 서버 구축이 필요 없으며, 서버 프로비저닝, 패치, 소프트웨어 설치 불필요.
- 자동 용량 조정: 테이블이 자동으로 확장 및 축소됨.
- 테이블 클래스 선택: 워크로드 및 접속 빈도에 따라 Standard 및 Standard-IA 테이블 클래스 선택 가능.
Amazon ElastiCache
- 인메모리 데이터베이스: 데이터를 메모리에 저장하여 빠르게 처리.
- 용도: 주로 실시간 애플리케이션의 데이터베이스 처리 지원.
- 두 가지 버전:
-ElastiCache for Memcached: 자주 접근하는 데이터를 메모리에 저장하고 빠르게 처리하는 캐싱 시스템.
-ElastiCache for Redis: 데이터베이스, 캐시, 메시지 브로커 및 대기열 용도로 사용되는 인메모리 데이터베이스로, 1ms 미만의 지연으로 빠른 데이터 처리 가능.
Amazon Redshift
- 데이터 웨어하우스 서비스: PostgreSQL 기반의 관리형 데이터 웨어하우스.
- 특화: OLAP(Online Analytical Processing)에 적합하며, 분석 쿼리에 최적화된 열 기반 스토리지 사용.
- 대량 병렬 처리(MPP): 빠르고 비용 효율적인 비즈니스 의사결정 지원.
- 통합: 다른 AWS 서비스와 쉽게 통합 가능.
Amazon Athena
- 서버리스 쿼리 서비스: Amazon S3에 저장된 데이터를 SQL 쿼리로 분석.
- 지원하는 데이터 형식: CSV, JSON, ORC, Avro, Parquet.
- 요금: 스캔한 데이터 TB당 5달러.
- 제약사항: 동시 실행 쿼리 수 최대 5개, S3 버킷 생성 최대 100개, 데이터베이스 생성 최대 10,000개.
DMS (Database Migration Service)
- 데이터베이스 마이그레이션 서비스: 데이터베이스 간의 쉽고 빠른 마이그레이션 지원.
- 마이그레이션 유형:
-Homogeneous migration: 같은 데이터베이스로 마이그레이션.
-Heterogeneous migration: 다른 데이터베이스로 마이그레이션 (자동 변환 수행). - 다운타임 최소화: 마이그레이션 중에도 원본 데이터베이스 사용 가능.
출처: 공준익 교수님 수업자료
'네트워크 보안' 카테고리의 다른 글
| 클라우드 기타 용어 간단 정리 (0) | 2024.11.25 |
|---|---|
| 클라우드를 실현하는 기술 (0) | 2024.11.25 |
| 클라우드 서비스 (0) | 2024.11.25 |
| 클라우드 기초 (0) | 2024.09.10 |

